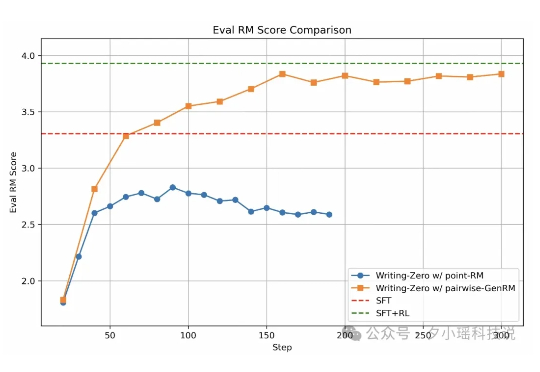
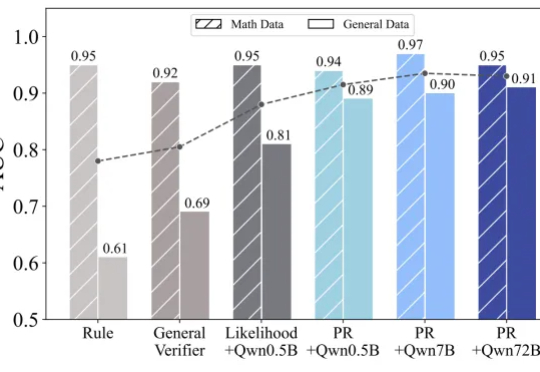
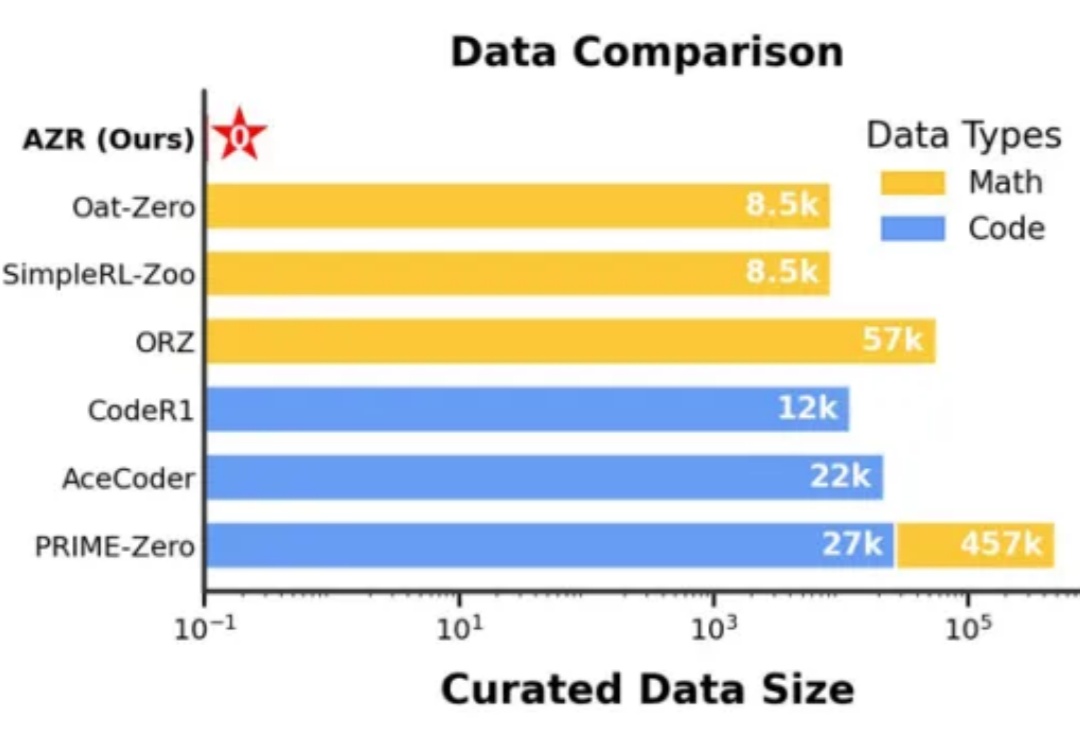
Generalist之后,罗剑岚团队推出LWD,也要变革具身智能训练范式
Generalist之后,罗剑岚团队推出LWD,也要变革具身智能训练范式智元机器人的办公室里,最近员工们一上班就能看到机器人熟练地切着水果:这么全面的能力是如何做到的?答案是直接在真实环境中搞大规模分布式强化学习训练。它们使用的是全新的具身智能训练范式:面向通用机器人策略的分布式多机强化学习(LWD)。这一套技术捅破了当前VLA的「天花板」。
来自主题: AI技术研报
6655 点击 2026-04-30 13:52